
Most developers consider that writing raw SQL (Structured Query Language) is a bad practice. The main arguments against it are that Object Relational Mappers (ORMs):
- Abstract several SQL dialects.
- Have a flat learning curve unlike SQL.
- Optimize queries.
ORMs allow you to abstract queries in an almost magical way:
# INSERT INTO user (name, age)
# VALUES ('Bob', 18)
# ON CONFLICT(name)
# DO UPDATE SET name = EXCLUDED.name
# RETURNING name, age
User user = new User("Bob", 18)
# UPDATE user
# SET age = 17
# WHERE name = 'Bob'
user.age = 17

Before we start
The contents of this article are a mix between my work experience and the great insights Mastering PostgreSQL in Application Development book provides.
The code for this article can be found here and it can be downloaded with the following command:
git clone \
--depth 2 \
-b blog \
https://github.com/alexdesousa/alexdesousa.github.io.git examples && \
cd examples && \
git filter-branch \
--prune-empty \
--subdirectory-filter examples/f1 HEAD
“My ORM abstracts several SQL dialects”
In my experience, I’ve found that it’s more likely for an application to be re-written in another language e.g. Ruby to Elixir than actually migrating the data from one database to another e.g. MySQL to PostgreSQL.
Additionally, running the database migrations in a different database is not a walk in the park either. Complex applications end up adding custom SQL to their migrations in order to optimize or automate certain processes: database extensions, indexes and triggers.
And then, the data needs to be migrated e.g. pgloader is an amazing tool that migrates data from MySQL, SQLite or MSSQL to PostgreSQL. However, sometimes these tools don’t work correctly or they are nonexistent.

“My ORM has a flat learning curve unlike SQL”
SQL is different. It’s a functional language and most programmers are used to imperative languages. It’s also hard to master.
Ironically, the queries are almost in natural language e.g. if we show the following sentences to someone who doesn’t know SQL, probably they’ll know they have the same objective:
- Get the
nameandageof everyclientolder than or equal to18. SELECT name, age FROM client WHERE age ≥ 18
ORMs specifically work great for simple queries. However, when you need a more complex query, you end up doing certain workarounds to bypass the ORMs limitations:
- Writing raw SQL directly.
- Querying the database several times (sometimes unknowingly) to retrieve the data we need and doing the computation in our language instead of the database.
For now I’ll focus on the second approach and I’ll talk about the first one later. It’s easier to see it with a small example:
Given the following subset of tables from the Chinook database:
Chinook database subset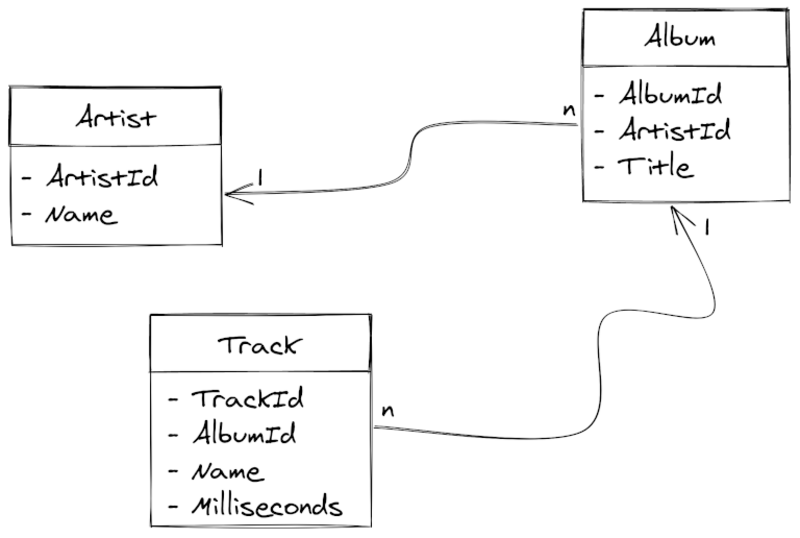
We want to know the duration of every album Pearl Jam has ever made (or at least the ones listed in the database). In an OO language we would do something like:
Artist artist = Artist.one(name: "Pearl Jam")
for album in Album.all(artistId: artist.id)
ms = 0
for track in Track.all(albumId: album.id)
ms += track.milliseconds
print("#{album.title} | #{format_time(ms)}")
For a developer who doesn’t know SQL, this would seem like reasonable code. In reality, it’s highly inefficient:
-
We’re requesting one artist by name:
SELECT * FROM "Artist" WHERE "Name" = 'Pearl Jam' -
Then requesting all albums by artist id:
SELECT * FROM "Album" WHERE "ArtistId" = artist.id -
For every album, we’re requesting the tracks by album id:
SELECT * FROM "Track" WHERE "AlbumId" = album.id
This database contains 5 Pearl Jam albums, so we would be querying the database 7 times. The magic behind the ORM is deceiving us. In every round trip to the database, we need to consider two things:
- Time the query takes to execute.
- Time the network transmits the data.
Good ORMs introduce ways of dealing with this type of problem. However, knowing we need to use those tools in order to have good performance in our queries requires knowing SQL.
So, going back to the title of this section: Do ORMs really have a flat learning curve? Considering programmers need to know SQL to understand the tools ORMs offer and SQL is hard, then I guess they have not.

The previous problem can be solved with one query:
Note: Chinook database has capitalized table and column names. That’s why they need to be between double quotes.
SELECT "Album"."Title" AS album,
SUM("Track"."Milliseconds") * interval '1 ms' AS duration
FROM "Album"
INNER JOIN "Artist" USING("ArtistId")
LEFT JOIN "Track" USING("AlbumId")
WHERE "Artist"."Name" = 'Pearl Jam'
GROUP BY album
ORDER BY album
and our result would be already formatted:
album | duration
-------------------------+-------------
Live On Two Legs [Live] | 01:11:18.954
Pearl Jam | 00:49:43.857
Riot Act | 00:54:16.468
Ten | 00:53:25.871
Vs. | 00:46:17.674
“My ORM optimizes queries”
Good ORMs do optimize queries. Usually they optimize queries for the most common cases. However, if the problem we’re solving is not covered by these optimizations, it can be a real head-scratcher.
In the end, we end up with a subpar solution or writing raw SQL to overcome the limitations.

Language Mappers
There are alternatives to ORMs. In Elixir, we have Ecto. It’s not an ORM, but a language mapper. It gives you a Domain Specific Language (DSL) for dealing with SQL queries in Elixir e.g. again if we want to know the duration of every album Pearl Jam has ever made (or the 5 listed in this database), we would do the following:
query =
from al in Album,
inner_join: ar in Artist, on: al.artistId == ar.artistId,
left_join: tr in Track, on: tr.albumId == ar.albumId,
where: ar.name == "Pearl Jam"
group_by: al.title
order_by: al.title
select: %{album: al.title, duration: sum(tr.milliseconds)}
Repo.all(query)
Language mappers require developers to know SQL, but allows them to almost never leave the comfort of their language. That “almost” is important.

Though not everything is sunshine and rainbows. Language mappers try to abstract several SQL dialects in an unified DSL. This means that not all the SQL of our database is going to be included in this DSL.
To overcome this limitation, Ecto introduces the concept of fragments. Fragments are pieces of custom SQL code that can be added to our queries e.g. given the following subset from Ergast Developer API database:
Ergast Developer API database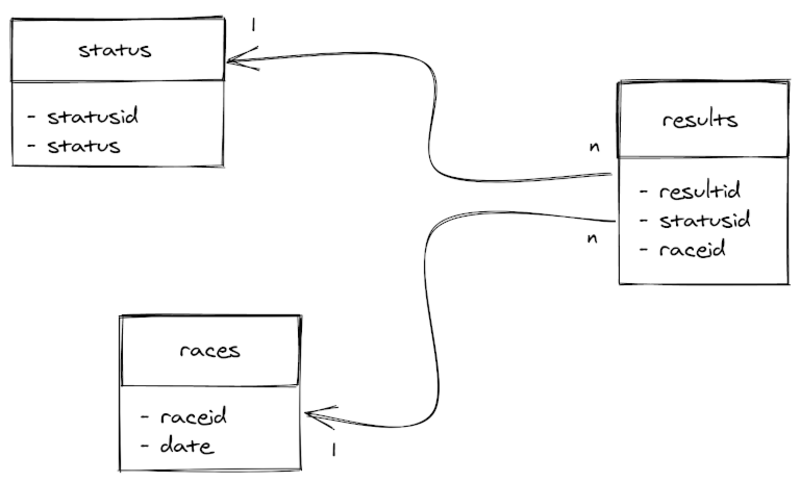
Let’s say we want to get the percentage of accidents per participant in F1 seasons between the years 1974 and 1990. In SQL, we would have the following:
WITH accidents AS
(
SELECT EXTRACT(year from races.date) AS season,
COUNT(*) AS participants,
COUNT(*) FILTER(WHERE status = 'Accident') AS accidents
FROM f1db.results
JOIN f1db.status USING(statusid)
JOIN f1db.races USING(raceid)
GROUP BY season
)
SELECT season,
ROUND(100.0 * accidents / participants, 2) AS percentage
FROM accidents
WHERE season BETWEEN 1974 AND 1990
ORDER BY season
Now, when translating this query to Ecto, we’ll have to use fragments:
# NOTE: The schema definition is omitted.
from = 1974
to = 1990
accidents =
from re in Result,
join: st in assoc(re, :status),
join: ra in assoc(re, :race),
group_by: fragment("season"),
select: %{
season: fragment("EXTRACT(year from ?)", ra.date),
participants: fragment("COUNT(*)"),
accidents: fragment("COUNT(*) FILTER(WHERE status = 'Accident')")
}
query =
from a in subquery(accidents),
where: fragment("? BETWEEN ? AND ?", a.season, ^from, ^to),
select: %{
season: a.season,
percentage: fragment("ROUND(100.0 * ? / ?, 2)", a.accidents, a.participants)
}
F1.Repo.all(query)
The code above is hard to read, hard to write and error prone. Yet we don’t have any performance improvements in our query. A maintenance nightmare.
We could re-write the previous Ecto query differently by encapsulating them in Elixir macros and then importing our custom DSL e.g:
defmodule CustomDSL do
import Ecto.Query
defmacro year(date) do
quote do
fragment("EXTRACT(year from ?)", unquote(date))
end
end
...
end
But again, we wouldn’t get any improvements performance-wise. Just readability… in Ecto. It was perfectly readable in SQL.
The consequences are clear. Developers need knowledge of:
- The specific SQL dialect (in this case PostgreSQL dialect).
- Ecto’s API and its limitations.
- Elixir’s macros for fragment encapsulation.
Additionally, now they need to maintain a new custom DSL API with its documentation. If we only have a few of this complex queries in our project, is it worthy?
What’s worse, after the refactor, we could end up with a subpar solution or wasting our time entirely.
Raw SQL
So far we’ve seen ORMs and language mappers are good for general problems we might encounter. However, some other problems are better left in raw SQL.
ORMs, language mappers and database adapters usually provide an API for running raw SQL. In Elixir, Ecto and Postgrex give us the function query/2 e.g. in Ecto we would do the following:
query =
"""
WITH accidents AS
(
SELECT EXTRACT(year from races.date) AS season,
COUNT(*) AS participants,
COUNT(*) FILTER(WHERE status = 'Accident') AS accidents
FROM results
JOIN status USING(statusid)
JOIN races USING(raceid)
GROUP BY season
)
SELECT season,
ROUND(100.0 * accidents / participants, 2) AS percentage
FROM accidents
WHERE season BETWEEN $1 AND $2
ORDER BY season
"""
Ecto.Adapters.SQL.query(F1.Repo, query, [1974, 1990])
There are some things I’d like to point out from the previous code:
$1and$2are the query parameters: The numbers indicate the position in the parameter list. If we add status as a variable instead of the constant'Accidents', we would need to update the other indexes.- The query is a string: usually editors wouldn’t highlight the SQL syntax inside the string.
-
The
columnsandrowsare separated in the result:{:ok, %Postgrex.Result{ columns: ["season", "percentage"], command: :select, connection_id: 206, messages: [], num_rows: 17, rows: [ [1974.0, #Decimal<3.67>], [1975.0, #Decimal<14.88>], [1976.0, #Decimal<11.06>], [1977.0, #Decimal<12.58>], [1978.0, #Decimal<10.19>], ... }}
The complexity it’s still there.
Meet AyeSQL
Inspired by Clojure library Yesql, AyeSQL tries to find a middle ground between raw SQL strings and SQL language mappers by:
- Keeping SQL in SQL files.
- Generating Elixir functions for every query.
- Working out of the box with PostgreSQL using Ecto or Postgrex.
- Being extendable to support other databases and outputs.
- Allowing some query composability.
Defining the same query in AyeSQL, we would need the following:
-
A file for defining our query in raw SQL:
-- file: lib/f1/query/season.sql -- name: get_accidents -- docs: Gets accidents in a season range. WITH accidents AS ( SELECT EXTRACT(year from races.date) AS season, COUNT(*) AS participants, COUNT(*) FILTER(WHERE status = 'Accident') AS accidents FROM f1db.results AS results JOIN f1db.status AS status USING(statusid) JOIN f1db.races AS races USING(raceid) GROUP BY season ) SELECT season, ROUND(100.0 * accidents / participants, 2) AS percentage FROM accidents WHERE season BETWEEN :from AND :to ORDER BY season -
A file for declaring our queries as Elixir functions:
# file: lib/f1/queries.ex import AyeSQL, only: [defqueries: 3] defqueries(F1.Query.Season, "query/season.sql", repo: F1.Repo) -
Modify our configuration to run the queries by default:
# file: config/config.exs import Config config :ayesql, run?: true
Then we can call our query as follows:
iex> F1.Query.Season.get_accidents(from: 1974, to: 1990)
{:ok,
[
%{percentage: #Decimal<3.67>, season: 1974.0},
%{percentage: #Decimal<14.88>, season: 1975.0},
%{percentage: #Decimal<11.06>, season: 1976.0},
%{percentage: #Decimal<12.58>, season: 1977.0},
%{percentage: #Decimal<10.19>, season: 1978.0},
...
]}
I don’t know about you, but IMHO this seems like a maintainable way of dealing with complex SQL queries.

AyeSQL provides query runners for Ecto and Postgrex out-of-the-box. In the previous example we used Ecto’s runner. If we need a different output or query a different database e.g. MSSQL, we could implement the behaviour AyeSQL.Runner for our use case.
Note: In the past year, my team and I had to write an Elixir application with a pre-existent MSSQL database.
AyeSQL.Runnerbehaviour and TDS library allowed us to query the database with ease.
Conclusion
I’m hoping this article helps change the negative reputation raw SQL queries have.
Yesql inspired libraries like AyeSQL, can help you to be more productive when your ORM or language mapper have failed you.

I’ll write more about AyeSQL features in future articles, but for now happy coding!
Cover image by Austin Neill